- Create Date: 2022-05-02
- Update Date: 2024-11-25
数仓相关
数仓基础
数仓基建
-
什么是数据仓库
以数据建模理念为基础,以消除数据孤岛为目的,通过一系列标准方法和工具,解决大数据计算中如质量、复用、扩展、成本等问题,驱动业务发展。 -
数据仓库特点
面向主题的,继承的,稳定的,反应历史变化 -
六大概念
- 分层
- 为了解耦合、分布执行、降低出问题的风险
- 空间换时间,使用预计算换取数据使用的高效性
- 方便快速定位问题
- 分域
- 主题域:面向分析的,通常是联系较为紧密的数据主题的集合
- 数据域:一类业务活动单元的集合,如日志、交易等
-
分类: 如元数据、主数据、参考数据等
-
维度: 由独立不重叠的数据元素组成的数据集,所构成的可进行统计的对象。即我们观察某一事务的一个角度
-
粒度: 事实表中一条记录所表达的业务细节程度
- 事实
-
OneData体系
OneData体系是阿里数据中台的核心方法论,其包含了三个方面内容:OneModel即建立企业统一的数据公共层,从设计、开发、部署和使用上保障了数据口径规范和统一,实现数据资产全链路管理,提供标准数据输出。OneID即建立业务实体要素资产化为核心,实现全域链接、标签萃取、立体画像,其数据服务理念根植于心,强调业务模式。OneService即数据被整合和计算好之后,需要提供给产品和应用进行数据消费,为了更好的性能和体验,需要构建数据服务层,通过统一的接口服务化方式对外提供数据服务。 -
模型调优
- 完善度: 应用层访问汇总层数据的查询比例、跨层应用率、是否可以快速响应业务方的需求
-
复用度:模型引用系数->模型被读取并产出下游模型的平均数量
-
规范度:主题域归属、分成信息、命名规范、表&字段命名
-
稳定性:SLA保证
-
扩展性:模型是否有冲突
-
准确性&一致性:数据质量保证
-
健壮性:底层模型不受快速迭代的业务影响
-
低成本
数据治理
a. 数据规范
b. 元数据管理
c. 主数据管理
d. 数据安全
e. 数据质量管理:数据产生/数据接入/数据存储/数据的处理和分析/数据传输/数据展现
f. 数据成本管理
指标体系
大数据技术
spark相关
- spark的程序运行流程、调度流程、本地化调度、内存管理模型
-
sparksql的解析流程

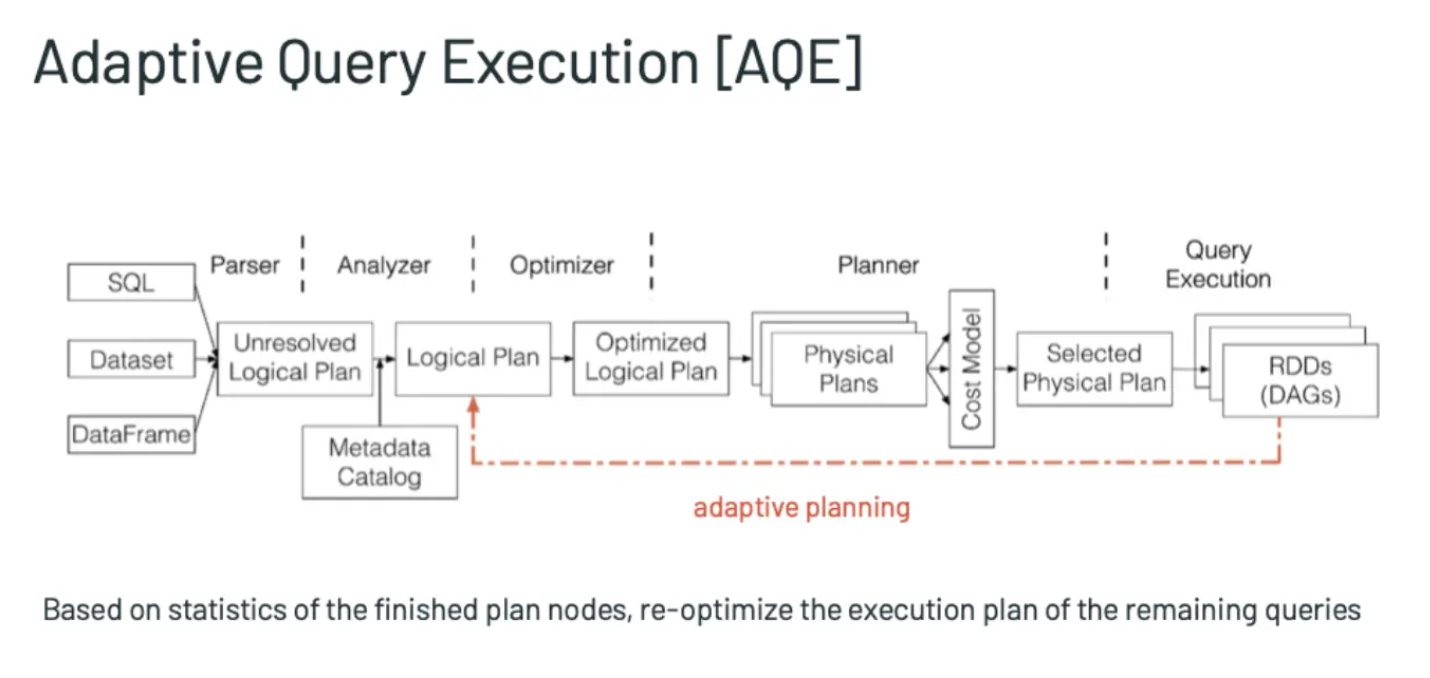
优化器(RBO、CBO、AQE): 优化器
- 动态分区裁剪、动态优化数据倾斜、动态选择join策略相关参数
- AQE开关
spark.sql.adaptive.enabled=true默认false,为true时开启自适应查询,在运行过程中基于统计信息重新优化查询计划spark.sql.adaptive.forceApply=true默认false,自适应查询在没有shuffle或子查询时将不适用,设置为true将始终使用spark.sql.adaptive.advisoryPartitionSizeInBytes=64M默认64MB,开启自适应执行后每个分区的大小。合并小分区和分割倾斜分区都会用到这个参数
- 开启合并shuffle分区
spark.sql.adaptive.coalescePartitions.enabled=true当spark.sql.adaptive.enabled也开启时,合并相邻的shuffle分区,避免产生过多小taskspark.sql.adaptive.coalescePartitions.initialPartitionNum=200合并之前shuffle分区数的初始值,默认值是spark.sql.shuffle.partitions,可设置高一些spark.sql.adaptive.coalescePartitions.minPartitionNum=20合并后的最小shuffle分区数。默认值是Spark集群的默认并行性spark.sql.adaptive.maxNumPostShufflePartitions=500reduce分区最大值,默认500,可根据资源调整
- 开启动态调整Join策略
spark.sql.adaptive.join.enabled=true与spark.sql.adaptive.enabled都开启的话,开启AQE动态调整Join策略
- 开启优化数据倾斜
spark.sql.adaptive.skewJoin.enabled=true与spark.sql.adaptive.enabled都开启的话,开启AQE动态处理Join时数据倾斜spark.sql.adaptive.skewedPartitionMaxSplits=5处理一个倾斜Partition的task个数上限,默认值为5;spark.sql.adaptive.skewedPartitionRowCountThreshold=1000000倾斜Partition的行数下限,即行数低于该值的Partition不会被当作倾斜,默认值一千万spark.sql.adaptive.skewedPartitionSizeThreshold=64M倾斜Partition的大小下限,即大小小于该值的Partition不会被当做倾斜,默认值64Mspark.sql.adaptive.skewedPartitionFactor=5倾斜因子,默认为5。判断是否为倾斜的 Partition。如果一个分区(DataSize>64M*5)或(DataNum>(1000w*5)),则视为倾斜分区。spark.shuffle.statistics.verbose=true默认false,打开后MapStatus会采集每个partition条数信息,用于倾斜处理
- sparksql怎么处理count distinct:count distinct在spark中的运行机制
flink相关
kafka相关
sql相关
sql练习
sql总结
- 分桶来解决大表关联问题
- 建分桶表
CLUSTERED BY (name) SORTED BY (name)INTO 5 BUCKETS -
插入数据 需要用
insert overwrite - 开启支持分桶
set hive.auto.convert.sortmerge.join=true;set hive.optimize.bucketmapjoin = true;set hive.optimize.bucketmapjoin.sortedmerge = true;
- 建分桶表
其他
技术相关
bitmap和布隆过滤器
bitmap
优点: 运算效率高,不需要进行比较和移位; 占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M 缺点: 所有的数据不能重复。即不可对重复的数据进行排序和查找。 只有当数据比较密集时才有优势
class MyBitMap:
def __init__(self, size):
if (size < 0):
return
self.size = size // 8 + 1
self.bitmap = bytearray(self.size)
def append(self, num):
self.bitmap[num // 8] = self.bitmap[num // 8] | (1 << num % 8)
def delete(self, num):
self.bitmap[num // 8] = self.bitmap[num // 8] & (~(1 << num % 8))
def find(self, num):
return self.bitmap[num // 8] & (1 << num % 8) != 0
if __name__ = '__main__':
mybitmap = MyBitMap(1000)
mybitmap.append(800)
mybitmap.append(19)
mybitmap.append(80)
mybitmap.find(800)
mybitmap.find(77)
mybitmap.delete(19)
布隆过滤器
通过一个很长的二进制向量(bitmap)和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。 可以解决网页 URL 去重、垃圾邮件识别、大集合中重复元素的判断和缓存穿透等问题。
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterDemo {
public static void main(String[] args) {
int total = 1000000; // 总数量
BloomFilter<CharSequence> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), total);
// 初始化 1000000 条数据到过滤器中
for (int i = 0; i < total; i++) {
bf.put("" + i);
}
// 判断值是否存在过滤器中
int count = 0;
for (int i = 0; i < total + 10000; i++) {
if (bf.mightContain("" + i)) {
count++;
}
}
System.out.println("已匹配数量 " + count);
}
}
